
A Comprehensive Approach to Competition: Improve the Funding Mechanism for Ethereum Projects
By: Theo
Participating in the Improve the Funding Mechanism for Ethereum Projects challenge on Pond and huggingface was an exciting opportunity to apply data science techniques to a real-world problem: predicting funding for projects based on various metrics. This post outlines my approach, detailing the steps I took from data collection to model evaluation.
Data Collection and Exploration
The first step in my journey was gathering data from multiple sources. I collected datasets from the Pond competition, Hugging Face, and the DeepFunding GitHub repository.
Training data example :
| id | project_a | project_b | weight_a | weight_b | total_amount_usd | funder | quarter |
|---|---|---|---|---|---|---|---|
| 8 | nethermindeth | go-ethereum | 0.651286 | 0.348714 | 1143418 | optimism | 2024-10 |
| 9 | grandine | go-ethereum | 0.349613 | 0.650387 | 613060 | optimism | 2024-10 |
| … | … | … | … | … | … | … | … |
I noticed that huggingface training dataset is slightly different than the training dataset provided by cryptopond and deepfunding github repo. Its not containing amount_of_usd, funder, and quarter column. Using only these features were insufficient to build a robust machine learning model.
To enrich this dataset, I create a list of the unique project repo urls and retrieve additional information using GitHub API, including metrics such as stars, forks, commits, and other relevant data like ‘used by’ number, open/closed issues and pull requests using beautifulsoup4. I also extracted the README files for each repository, recognizing their potential to provide valuable insights into project characteristics.
Data Preprocessing and Feature Engineering
Given the often lengthy nature of README files, I utilized BART, a powerful language model, to summarize these documents effectively. BART was chosen for its strong performance in text summarization tasks, allowing me to distill essential information while preserving context.
In this code i use BART large, with 12 encoder and decoder layer and has 400M parameters.
import pandas as pd
import requests
from transformers import BartForConditionalGeneration, BartTokenizer
# Step 1: Load the BART model and tokenizer
model_name = "facebook/bart-large-cnn"
tokenizer = BartTokenizer.from_pretrained(model_name)
model = BartForConditionalGeneration.from_pretrained(model_name)
def summarize_readme(readme_content):
if readme_content:
inputs = tokenizer.encode("summarize: " + readme_content, return_tensors="pt", max_length=1024, truncation=True)
summary_ids = model.generate(inputs, max_length=50, min_length=25, length_penalty=2.0, num_beams=4, early_stopping=True)
return tokenizer.decode(summary_ids[0], skip_special_tokens=True)
return "No content to summarize"
# Step 2: Process each repository
summaries = []
for repo_url in unique_urls_list:
readme_content = fetch_readme(repo_url)
summary = summarize_readme(readme_content)
summaries.append({'repo_url': repo_url, 'summary': summary})
# Convert summaries to DataFrame for easy viewing
summaries_df = pd.DataFrame(summaries)
# Step 3: Save the summaries to a CSV file
summaries_df.to_csv('github_readme_summaries.csv', index=False)
# Print the summaries DataFrame
print(summaries_df)Summarization result :
| Url | Summary |
|---|---|
| https://github.com/prettier-solidity/prettier-plugin-solidity | Prettier Solidity is a tool for automatically formatting your [Solidity] code. Prettier only works with valid code. If there is a syntax error, nothing will be done and a parser error will be thrown. |
| https://github.com/bluealloy/revm | Revm is an EVM written in Rust that is focused on speed and simplicity It has a fast and flexible implementation with a simple interface and embedded Host. It passes all Ethereum/tests |
| … | … |
Addressing data skewness was another critical preprocessing step. Many of the collected metrics exhibited positive skew, which can adversely affect model performance. To tackle this, I applied normalization techniques, including calculating ratios and performing logarithmic transformations. These transformations helped create a more balanced data distribution, making it suitable for model training.
Effectiveness of logarithmic transformation is shown in images below.
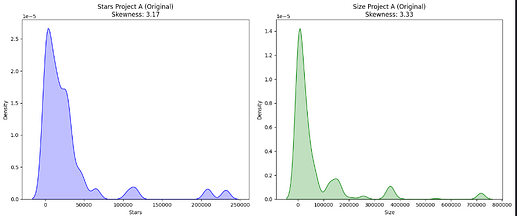
Before Log transformation
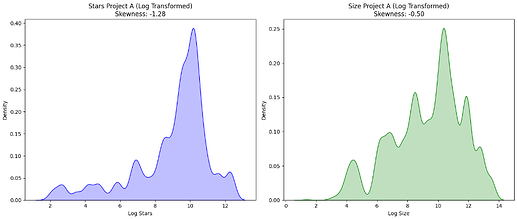
After log transformation
After merging the processed data with the original training and test sets, I ended up with a comprehensive dataset comprising 114 columns (including raw numerical data/before transformation). This rich feature set provided ample opportunities for model training. Additionally, I augmented the data by mirroring and concatenating project pairs, effectively doubling the dataset size. This augmentation aimed to enhance the model's ability to discern subtle patterns in pairwise comparisons.
One more thing that should be considered is the unbalanced dataset. Some project may appear in most of times, but the other project may only appear in less than 5 pairs. So i use minority class resampling to resample / duplicate minority class to balance the dataset.
# Iterate over each unique value in the 'project_a' column
for project, count in project_a_counts.items():
# Resample the dataframe for the current project
df_project = train_hf[train_hf['project_a'] == project]
n_samples = int(count * oversampling_factors[project])
if n_samples < count:
n_samples = count # Ensure at least the original count
df_project_oversampled = resample(df_project,
replace=True, # Sample with replacement
n_samples=n_samples, # To match the required factor
random_state=42) # Random state for reproducibility
oversampled_dfs.append(df_project_oversampled)
# Concatenate all the oversampled dataframes
train_hf_oversampled = pd.concat(oversampled_dfs)This native duplication approach may not be the best way to balance the data, but its kinda effective to lower the MSE score from around 5% to 7% with 90% confidence ratio in 20 evaluation.
Model Selection and Tuning: Embracing XGBoost
For this challenge, I opted for XGBoost, a Gradient Boosted Tree model renowned for its performance in regression tasks. To optimize the model's performance, I conducted a thorough parameter tuning process using GridSearchCV. This involved exploring a vast parameter space, a computationally intensive task that I facilitated by leveraging the resources available on Kaggle.
The final XGBoost parameters, determined through extensive experimentation, are as follows:
-
Hugging Face Dataset:
python xgb_regressor = xgb.XGBRegressor( objective='reg:squarederror', n_estimators=750, learning_rate=0.05, max_depth=8, subsample=1, colsample_bytree=0.1, random_state=42 ) -
Pond Dataset:
python xgb_regressor = xgb.XGBRegressor( objective='reg:squarederror', n_estimators=1000, learning_rate=0.05, max_depth=8, subsample=1, colsample_bytree=0.1, random_state=42 )
The model achieved promising results, with a Mean Squared Error (MSE) of approximately 0.06 on the Hugging Face test set and 0.0375 on the Pond test set.
Pond leaderboard as per 11 February 2025 :
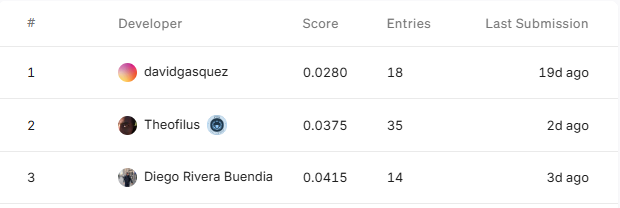
Is kinda hard to beat the #1 rank, davidgasquez that has 10 years+ experience in data science and data engineering 😃. But as a ML beginner, i am proud of myself and will keep improve my skill!
Key Considerations and Reflections
Throughout this challenge, I encountered valuable insights. One key observation was that adding more features doesn't necessarily translate to improved performance. In fact, excessive features can sometimes hinder generalization.
Another important aspect was the processing of README summaries. These summaries couldn't be directly used as categorical variables. Instead, I employed TF-IDF to transform them into a numerical representation suitable for model input. This transformation significantly improved model performance, reducing the MSE by 10-20%.
Conclusion
The Improve the Funding Mechanism for Ethereum Projects challenge provided a valuable learning experience, reinforcing the importance of meticulous data preprocessing and model tuning. While the journey involved challenges, the insights gained were invaluable. I look forward to exploring further enhancements and refinements to this approach in future endeavors, especially for the ongoing main contest entitled “**Quantifying Contributions of Open Source Projects to the Ethereum Universe”**
Updated 22 days ago